의존성
1. 선형 의존성
Airflow에서 선형 의존성을 가진 Task는 이전 Task의 결과가 다음 Task의 입력값으로 사용되기 때문에, 다음 태스크로 이동하기 전에 각 태스크가 완료되어야 한다.
Airflow에서는 >> 연산지 혹은 << 또는 set_upstream, set_downstream을 이용하여 태스크 간의 유형 관계를 나타낼 수 있다.
first_stream=PythonOperator(
# ...생략...
)
second_stream=PythonOperator(
# ...생략...
)
third_stream=PythonOperator(
# ...생략...
)
# 유형 1
# first_stream ~ third_stream 까지 차례로 수행된다.
frist_stream >> second_stream >> third_stream
# 유형 2
# 유형 1과 마찬가지로 first_stream ~ third_stream까지 차례로 수행된다.
# 후행Task.set_upstream(선행Task)
second_stream.set_upstream(first_stream)
third_stream.set_upstream(second_stream)
# 유형 3
# set_downstream
# 유형 1과 마찬가지로 first_stream ~ third_stream까지 차례로 수행된다.
# 선행Task.set_downstream(후행Task)
first_stream.set_downstream(second_stream)
second_stream.set_dwonstream(third_stream)의존성을 명시적으로 지정하면 얻는 이점은 순서가 명확하게 정의된다는 것이다.
이는 단순하게 수행시간을 예측하여 스케줄링을 하는것보다 확실하게 처리할 수 있다.
2. 팬인/팬아웃(Fan-in/Fan-out) 의존성
- 팬인(Fan-in) 의존성 : 여러 선행 Task들이 하나의 후행 Task에 연결되는것
- 팬아웃(Fan-out) 의존성 : 하나의 선행 Task가 여러개의 후행 Task에 연결되는것
# 시작 더미 Task
start=DummyOperator(task_id="start")
# 날씨 데이터를 받아오는 Task
get_weather=PythonOperator(
# ...생략...
)
# 코로나 현황 데이터를 받아오는 Task
get_covid=PythonOperator(
# ...생략...
)
# 날씨 데이터와 코로나 현황 데이터를 합치는 Task
join_data=PythonOperator(
# ...생략...
)
# 유형 1 (선형 의존성)
# 만약 날씨데이터와 코로나현황 데이터를 합쳐
# 날씨에 따른 코로나현황을 보고싶다면
# 선형 의존성을 사용하여 날씨 데이터를 받아오는 DAG
get_weather >> get_covid >> join_data
# 유형 2 (팬인 의존성)
# get_weather와 get_covid 두개의 Task가 모두 정상 수행되면
# join_data Task가 수행되어야 한다.
[get_weather, get_covid] >> join_data
# 유형 3 (팬아웃 의존성)
# get_weather와 get_covid는 서로 의존성이 없다.
# 따라서 병렬로 수행한다면 DAG의 수행속도를 높일 수 있다.
start >> [get_weather, get_covid]
# 최종
start >> [get_weather, get_covid] >> join_data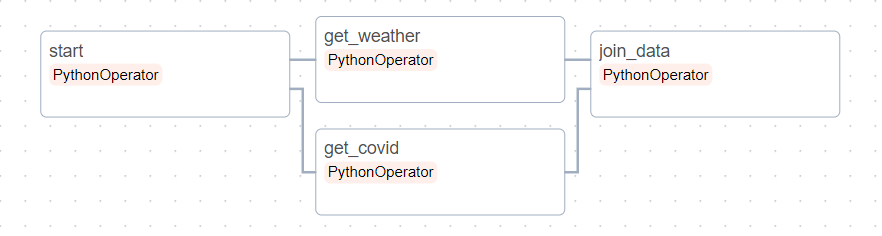
만일 유형 1이였다면 get_weather Task가 종료될때 까지 get_covid Task가 대기했어야 한다.
하지만 유형2,유형3인 팬인/팬아웃 의존성을 이용하여 get_weather와 get_covid를 병렬 실행시키고 두 Task가 종료되면 join_data Task가 수행되도록 하여 Task간의 흐름을 제어할 수 있다.
브랜치
1. Task 내부에서 브랜치
첫번째 방법은 실행 날짜 혹은 내부 조건 등을 이용하여 Task 내부에서 브랜치를 하는 방법이다.
해당 방식의 장점은 DAG 자체의 구조를 수정하지 않고 적용할 수 있다는 것이다.
하지만 코드 단위의 분기가 가능하며 유사한 Task 인 경우 수행할 수 있고 완전 다른 Task chain이 필요한 경우 Task 자체가 복잡해져 Task의 개발 난이도가 올라갈 수 있다.
def _get_file(**context):
if context["execution_date"] < CHANGE_DATE:
_get_file_old(**context)
else:
_get_file_new(**context)
get_file=PythonOperator(
python_callable=_get_file
# ...생략...
)위와 같은 Task 처럼 CHANGE_DATE 이전은 이전 함수를 CHANGE_DATE 이후는 새로운 함수를 사용하도록 변경할 수 있지만 더 복잡한 조건이 있는 경우 혹은 완전히 새로운 Task가 필요한 경우에는 적용이 힘들다.
또한 DAG가 수행하고 있으면 어떤 코드의 분기를 처리하고 있는지 파악하는것이 어렵다.
2. DAG 내부에서 브랜치
두번째 방법은 여러개의 개별 Task 세트들을 개발하고 DAG가 수행할 작업을 선택할 수 있도록 하는 것이다.
BranchPythonOperator는 작업 결과로 다운스트림 Task의 ID를 반환하고 실행할 다운스트림 Task의 리스트를 반환하면 참조된 모든 태스크를 실행한다.
def _get_file(**context):
if context["execution_date"] < CHANGE_DATE:
"get_file_old"
else:
"get_file_new"
branch_get_file=BranchPythonOperator(
task_id='pick_get_file'
python_callable=_get_file
# ...생략...
)
branch_get_file >> [get_file_old, get_file_new] >> join_Task >> # ...생략...하지만 이러한 경우 join_Task를 포함한 다운스트림 Task는 실행되지 않는다.
Airflow의 트리거 규칙은 모든 상위 태스크가 성공해야 해당 태스크를 실행할 수 있기 때문에 트리거 규칙은 all_success이다.
BranchPythonOperator 사용 시, 선택하지 않은 브랜치 작업들은 모두 건너뛰기 때문에 join_Task를 포함한 모든 다운스트림 Task 또한 실행하지 않는다.
이러한 문제를 해결하기 위해 join_Task의 트리거 규칙을 변경하여 업스트림 태스크 중 하나를 건너뛰더라도 트리거가 진행되도록 할 수 있다.
join_Task=PythonOperator(
# ...생략...
trigger_rule="none_failed",
)
이러한 접근방식 또한 여러 Task가 합쳐지다 보면 다양한 문제가 발생할 수 있어 적절한 Dummy Task를 추가하여 브랜치 조건을 명확하게 정해주어야 한다.
'데이터 엔지니어링 > AirFlow' 카테고리의 다른 글
| [Airflow] 기반의 데이터 파이프라인(9) - Executor (0) | 2023.10.26 |
|---|---|
| [Airflow] 기반의 데이터 파이프라인(8) - 워크플로우 트리거 (0) | 2023.10.21 |
| [Airflow] 기반의 데이터 파이프라인(7) - 태스크 간 데이터 공유 (0) | 2023.10.20 |
| [Airflow] 기반의 데이터 파이프라인(5) - 백필(BackFilling) (1) | 2023.10.14 |
| [Airflow] 기반의 데이터 파이프라인(4) - Airflow의 실행 날짜 이해 (0) | 2023.10.13 |
| [Airflow] 기반의 데이터 파이프라인(3) - 스케줄링 (1) | 2023.10.12 |