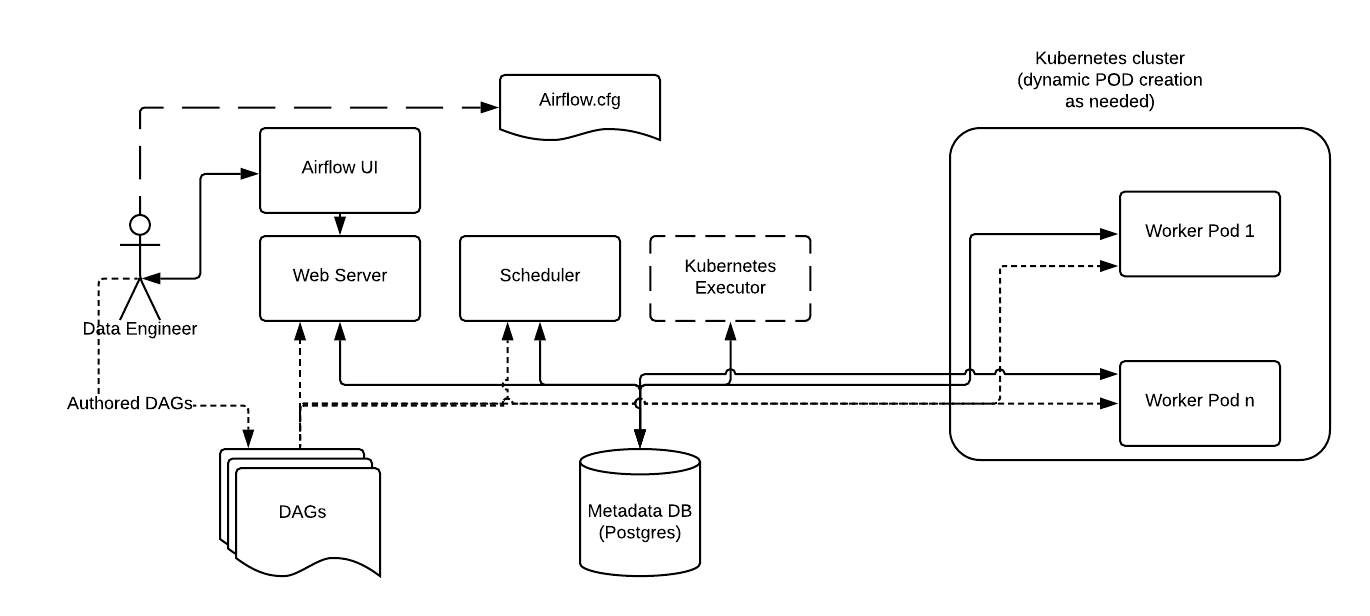
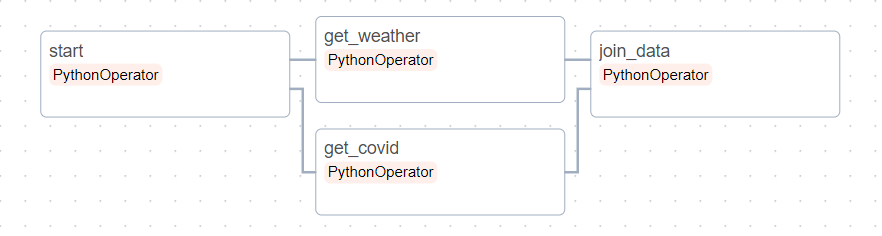
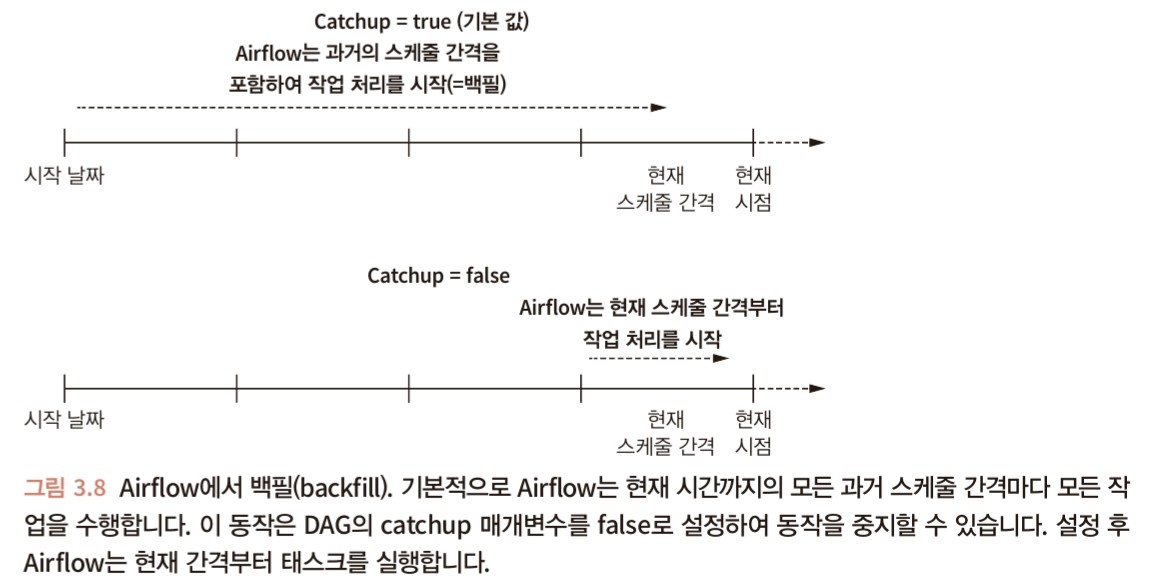
[데이터 엔지니어링/SQL] - [PL/SQL] 프로시저의 주요 기능 변수 선언 변수 선언은 지정된 데이터 유형의 값에 대한 저장 공간을 할당하고 참조할 수 있도록 저장 위치의 이름을 지정한다. NOT NULL 스칼라 변수나 상수에 NOT NULL 제약 조건을 넣을 수 있다. 이는 항목에 NULL 값을 할당하는 것을 방지한다. 프로시저는 길이가 0인 문자열을 NULL값으로 처리한다. 변수 선언 변수의 이름과 데이터의 유형을 지정한다. 변수 선언시 초기 값을 지정할 수도 있다. 값의 변경이 가능하다. 상수 선언 변하지 않는 값을 보유한다. 초기값이 필요하다. 변수에 값 할당 변수와 값은 호환 가능한 데이터 유형을 가져야 한다. 데이터의 유형은 암시적으로 해당 유형으로 변환될 수 있는 경우 다른 데이터 유형..