맵리듀스
맵리듀스는 큰 데이터를 다루는 job을 여러 태스크로 나누어 다수의 서버로 구성된 클러스터에서 병렬 처리하는 연산 모델이다.
맵리듀스는 맵과 리듀스라는 두 개의 기본 데이터 변환 연산에서 나왔다.
- 맵(Map) : 컬렉션의 모든 원소를 한 형태에서 다른 형태로 변환한다. 이때 입력된 key-value쌍은 0~N개의 key-value로 변환되며 같은 키를 가진 모든 key-value 쌍은 컬렉션의 형태로 동일한 리듀스 함수로 전달된다.
- 리듀스(Reduce) : 리듀스 함수는 값 컬렉션을 합계, 평균과 같은 값으로 변경하거나 다른 컬렉션으로 변경하여 최종 key-value쌍을 만든다.
하둡 인프라에서는 잡을 수행하기위해 많은 일을 처리하는데 수행되는 잡을 어떻게 맵-리듀스 태스크로 나누어 수행할지 결정하고 태스크가 쓰는 자원을 스케줄링 한다.
또한 클러스터 내 여러 노드 중 어떤 노드에 태스크를 보내야 하는지 결정한다. -- 네트워크 부하를 최소화 하기 위해 데이터가 있는 노드로 정한다.
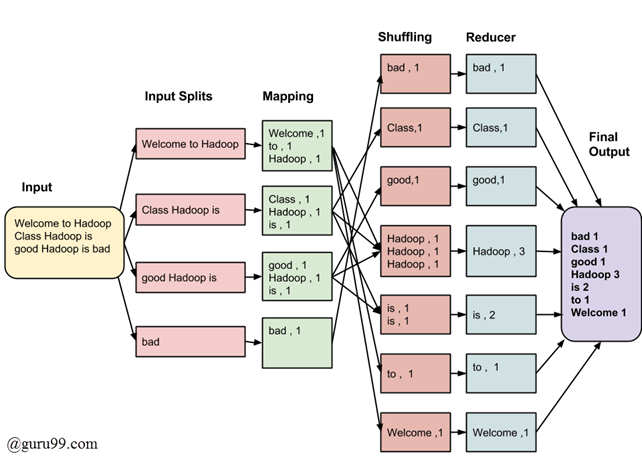
실제 맵리듀스(MR) 프로그래밍을 접해보지 못해 해당 부분은 추가적인 공부를 통해 보완해 나가고자 합니다.
MR 프로그래밍 및 관련 지식은 해당 페이지에 계속 작성 예정입니다.(2023.08.09)
'데이터 엔지니어링 > HIVE' 카테고리의 다른 글
| [Hive] 하이브 Query 주의 사항 (1) | 2023.10.25 |
|---|---|
| [Hive]하이브 관련 튜닝 옵션 정리 (1) | 2023.10.24 |
| [Hive] Hive-Intro-(1) (0) | 2023.08.09 |
| [Hive] Hive-시작-(0) (1) | 2023.08.08 |