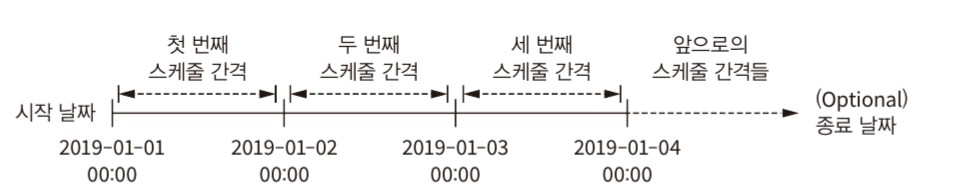
Airflow는 시작날짜, 스케줄 간격, 종료날짜의 세 가지 매개변수를 사용하여 DAG를 실행하는 시점을 제어할 수 있다. Airflow는 스케줄의 간격이 지난 시점에 DAG를 트리거 한다. 따라서 start_date 기준 schedule_interval이 도래한 가장 첫 시점에 DAG가 실행된다고 보면 된다. (실무에서 사용해보지 못했지만 오픈 카톡방인 '한국 데이터 엔지니어 모임' 에서 종종 물어보는 질문이다.) 책의 예시에서는 2019-01-03일의 데이터를 2019-01-04의 정각에 수집하는 예를 보여준다. 일반적인 스케줄러라면 시작일을 2019-01-04로 해야 하겠지만 Airflow에서의 start_date는 예약 간격의 실행 날짜 이기 때문에 start_date는 2019-01-03으로 주..